게이트 값
경기대학교 문헌정보학과 지능형 콘텐츠 연구실에 오신 것을 환영합니다.!
빅데이터와 인공지능 사회의 요구에 발맞춰 본 연구실은 인문학적 데이터의 구축, 인문학적 데이터 콘텐츠에 관한 연구 등과 함께 최신의 딥러닝 기술에 기반한 자연어 처리를 중점적으로 연구합니다.
빅데이터와 인공지능 사회의 요구에 발맞춰 본 연구실은 인문학적 데이터의 구축, 인문학적 데이터 콘텐츠에 관한 연구 등과 함께 최신의 딥러닝 기술에 기반한 자연어 처리를 중점적으로 연구합니다.

지도 교수

석사 과정

석사 과정

석사 과정

학사 과정

학사 과정

학사 과정

석사 졸업
근무지

석사 졸업
근무지

석사 졸업
근무지

석사 졸업
근무지

석사 졸업
근무지

석사 졸업
근무지

석사 졸업
근무지

석사 졸업
근무지
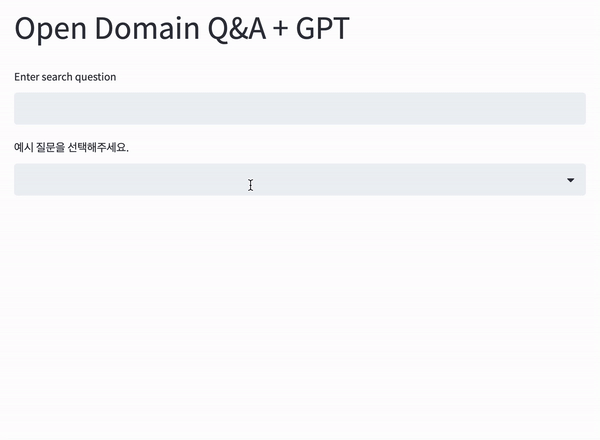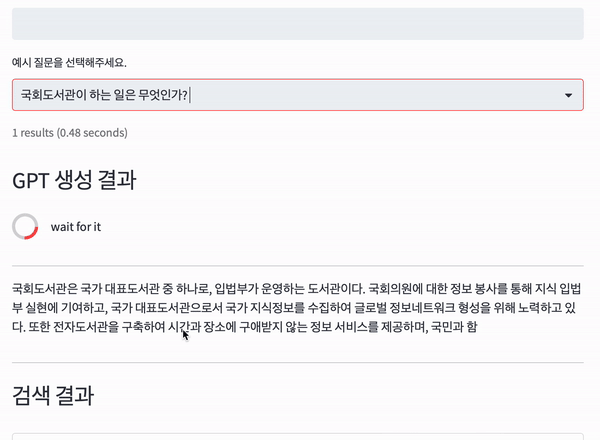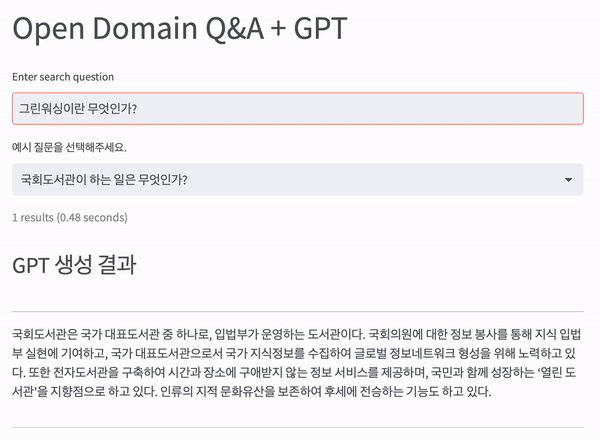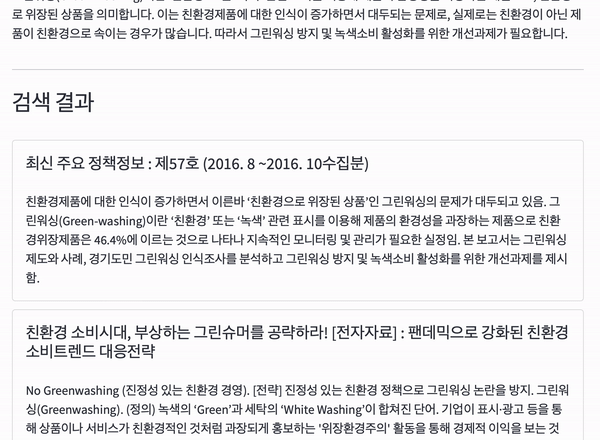
기존 ODQA(Open-domain question answering) 시스템을 Bing + ChatGPT와 같이 변경하기 위해 OpenAI의 GPT 3.5 API를 사용하였습니다.
검색엔진은 Elasticsearch 7.17 버전을 사용하였으며 Generator는 OpenAI의 GPT3.5 모델 중 gpt-3.5-turbo를 사용하였습니다.

구글 클라우드 비전 OCR 기능을 활용하여 이미지에서 수치 및 문자를 추출합니다.
생성된 수치 및 문자는 GPT 3.5 API의 프롬프트로 변형되며 생성합니다.이미지를 자연어로 설명하는 문장을 생성합니다.
Kobart 기술을 활용하여 신문기사의 제목 데이터를 학습한 언어 모델로, 주어진 기사 내용을 자동으로 분석하여 맞춤형 기사 제목을 생성합니다.
이를 통해 빠르고 정확한 기사 제목 작성이 가능하며, 더욱 효율적인 뉴스 제작 과정을 돕는 언어 모델 기능을 수행합니다.
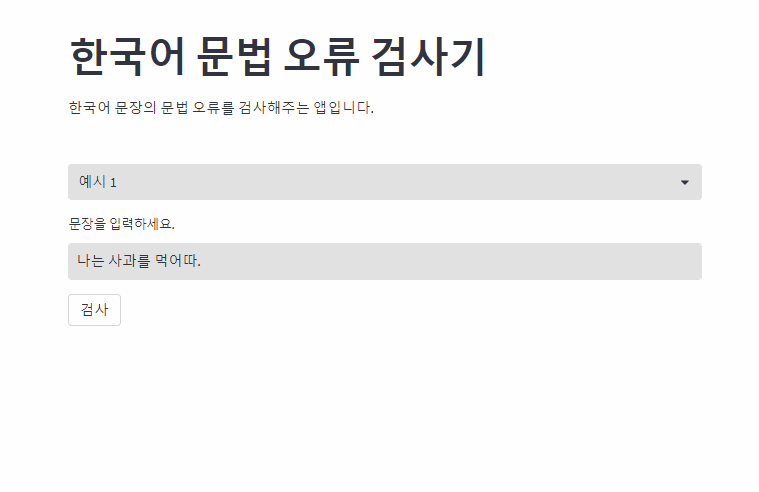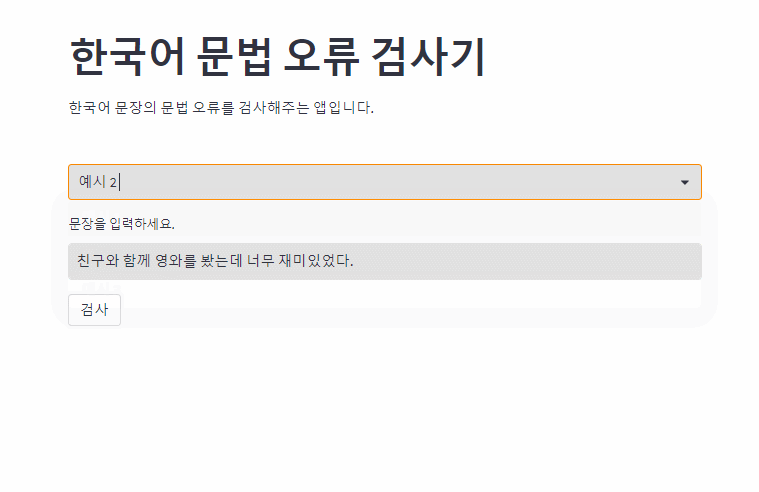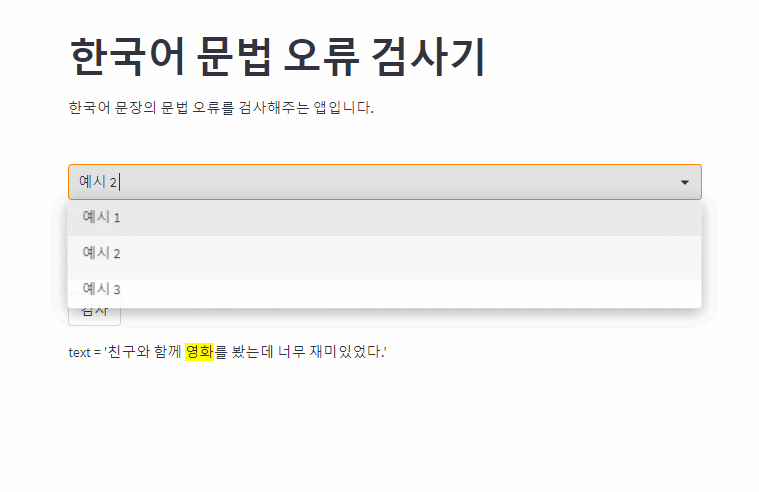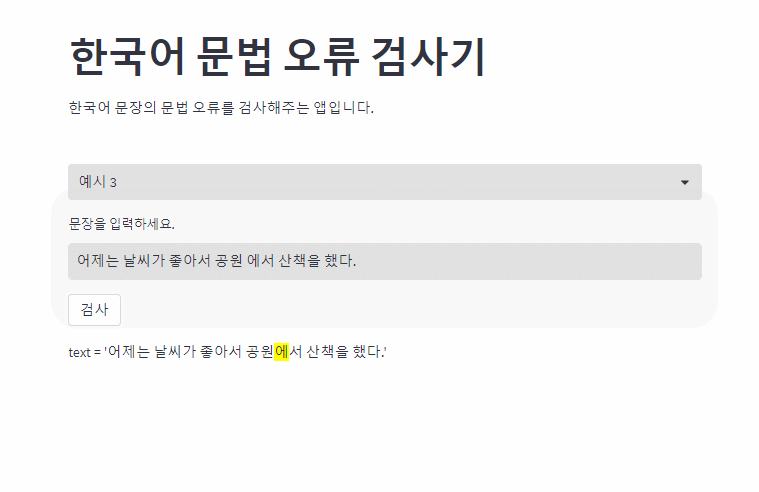
OpenAI의 GPT3.5를 사용한 한국어 문법 오류 교정 모델입니다. 문법 오류가 있는 부분을 하이라이팅을 통해 표시합니다.
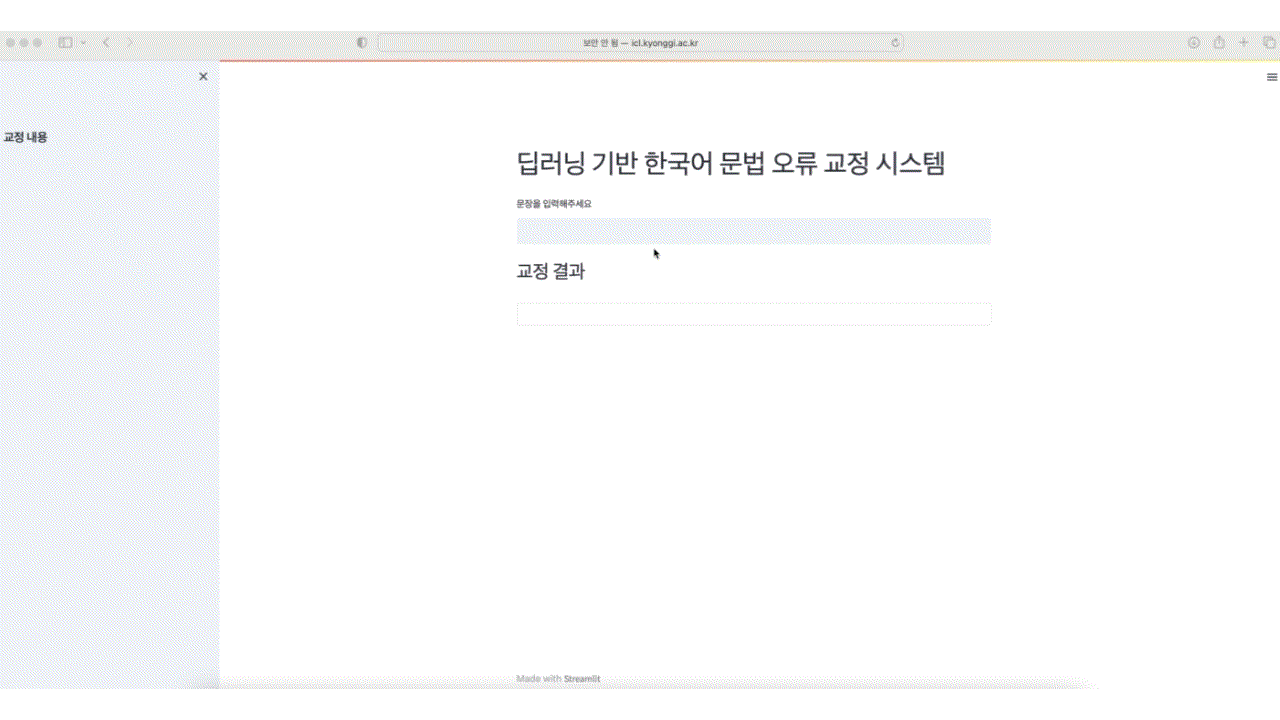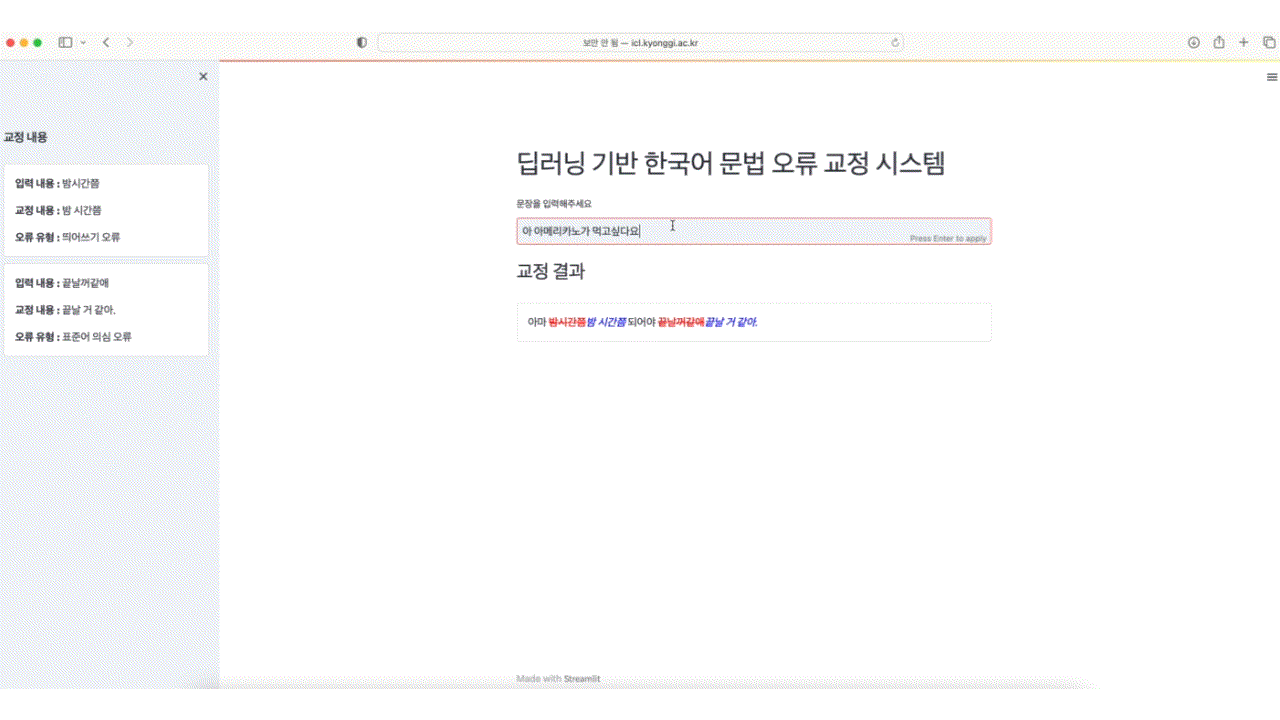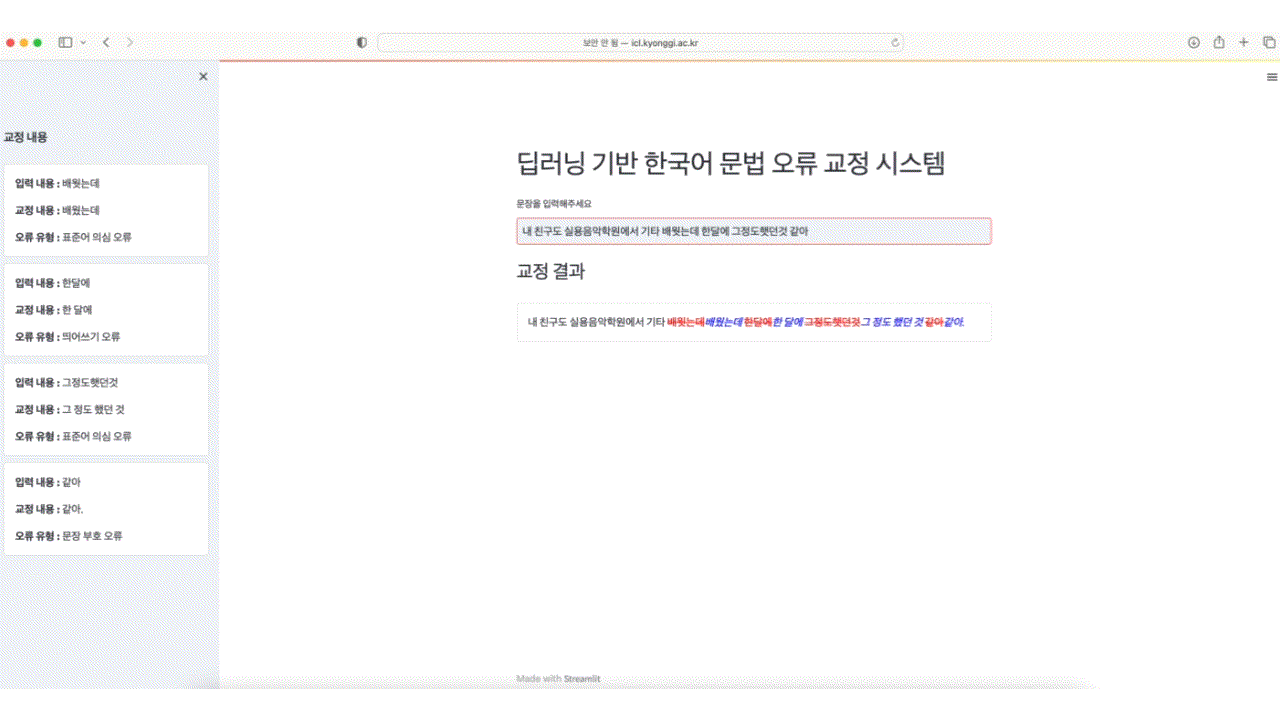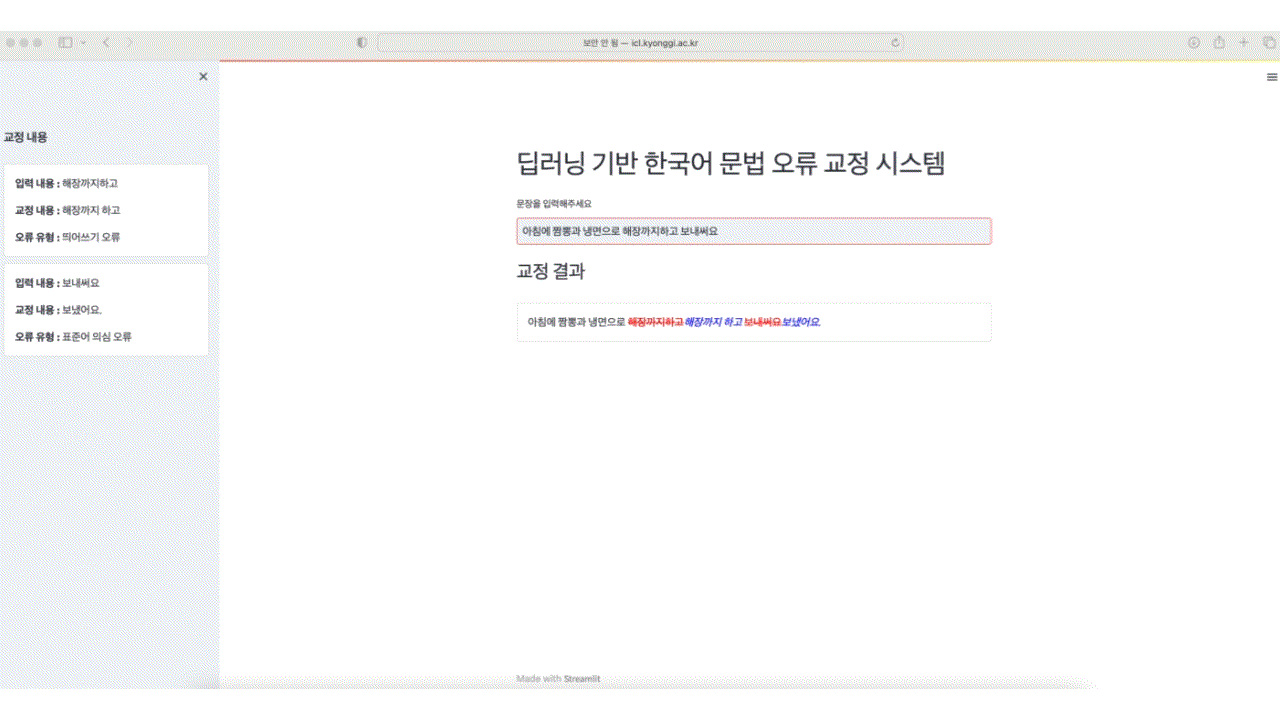
기존 딥러닝 기반 End-to-End 방식은 문법 오류 교정에서 효율성 측면에서 한계가 있었으며, 교정된 결과에 대한 설명을 제공하지 못하는 문제 또한 존재합니다.
본 연구는 효과적으로 문법 오류를 교정하고 이용자들에게 결과에 대해 설명할 수 있도록 문법 오류 교정 과정을 문법 오류 감지, 문법 오류 교정, 문법 오류 유형 분류로 세분화하여 파이프라인 기반 시스템을 구성하였습니다.

META에서 공개한 Llama 모델을 기반으로 파인튜닝을 수행한 alpaca모델을 기반으로 제작되었습니다.
본 모델은 약 20만쌍의 한국어 문법 오류 데이터셋을 학습하였으며 기존 alpaca모델에 비해 문법 오류 교정 task에서 뛰어난 성능을 보입니다.
본 시스템은 국회도서관 스마트 전자도서관 구축 사업의 일환으로 수행된 연구로 ODQA 기술을 활용하여 시스템을 구축하였습니다.
ODQA 시스템은 검색엔진, 재순위화 모델, 기계독해 모델로 구성되어 있으며, 한국어 사전학습 언어모델을 활용하여 모델을 학습하였습니다.
정선기, 안효준, 박수진, 심대훈, 이효진, 권지현, 최성필
참여자
발표논문
참여자
발표논문
참여자
발표논문
참여자
발표논문
참여자
발표논문
참여자
발표논문
참여자